Why 2023 was the most exciting year in computer vision history (so far)
Chatbots and LLMs dominated the public discourse in 2023, but computer vision also had a banner year. We've synthesized what happened in 10 key advances!


The 10 developments that reshaped computer vision
2023 was the year of chatbots and large language models (LLMs). From GPT-4 to Mixtral, to Llamas, Vicunas, Dolphins, and Orcas, it seemed like every day saw a new state-of-the-art model on some benchmark. At the same time, every week brought a new breakthrough in prompting, fine-tuning, quantizing, or serving LLMs. There was so much chatter about chatbots that it was hard to keep track of everything!
The LLM-mania was so intense and the headline-grabbing so severe that it dominated the public discourse on AI. But in reality, machine learning research and applications saw progress across many modalities, from images to audio!
Computer vision had a banner year in 2023. From new foundation models to accurate real-time detection, there’s far too much to fill a single blog post. Nevertheless, I’ve selected ten developments that I believe paint the greatest picture of computer vision’s progress.
💡If I missed something you believe is more important, share it in the comments :)
- YOLO Is Reborn: NextGen Object Detection
- SAM: The Foundation Model for Segmentation
- DINOv2: SOTA Models from Self-supervised Learning
- Gaussian Splatts Give NeRFs a Run for their Money
- T2I Models Turn the Corner
- LoRA: Flexible and Affordable Fine-tuning
- Ego-Exo4D: The Foundation Dataset for Video Perception
- T2V Models Arrive
- Multimodal LLMs
- LLM-aided visual reasoning
YOLO Is Reborn: NextGen Object Detection

For the greater part of a decade, the You Only Look Once (YOLO) family of models has been incredibly popular choices for near real-time object detection tasks. Prior to 2023, YOLO had already gone through many iterations, with popular variants including YOLOv5 and YOLOv8 (December 2022) from Ultralytics, YOLOv6 from Meituan, and YOLOv7.
In May, Deci AI released YOLO-NAS, a YOLO-style model created with the help of Neural Architecture Search (NAS). The model is faster and significantly more accurate than previous YOLO models, and has strong support for quantization. The smallest, quantized variant achieves a mean average precision (mAP) of 47.03 at just 2.36ms latency! YOLO-NAS also forms the basis for Deci’s state-of-the-art (SOTA) pose estimation model, YOLO-NAS-Pose.
📚Additional Resources:
- Tutorial on Fine-tuning YOLOv8
- Blog post on SOTA object detection with YOLO-NAS
- Gold-YOLO (TL;DR: version)
- DeciCoder and DeciLM-7B from Deci AI
Segment Anything: The Foundation Model for Segmentation

The Segment Anything Model (SAM) from Meta AI Research is arguably the first foundation model for segmentation tasks in computer vision. In the past, if you wanted to generate high-quality pixel-level classification predictions for your data, you would need to train a segmentation model from scratch.
SAM has completely changed the game. Now, you can segment everything in an image, or instance segment objects in an image via prompting the model with a bounding box or positive/negative keypoints. The GitHub repository has 40k stars and counting!
SAM and the 1.1 billion mask dataset co-developed with the model have already spawned tons of incredible related projects, including:
- Smaller, derivative segmentation models: FastSAM, MobileSAM, NanoSAM, EdgeSAM
- Composite applications: Recognize Anything, Inpaint Anything, Track-Anything, Grounded-Segment-Anything
- 3D segmentation applications: Segment Anything in 3D with NeRFs, Segment Anything 3D
- And medical segmentation models: MedSAM, SAM-Med3D
💡For specialized applications and deployed solutions, you will likely still want to train or fine-tune your own model!
📚Additional Resources:
- See What You Segment: SAM Blog Post
- FACET benchmark blog post
- SEEM: Segment Everything Everywhere All at Once
- SAM-HQ: Segment Anything in High Quality
DINOv2: SOTA Models from Self-supervised Learning

A standard technique in natural language processing applications is self-supervised learning, wherein the model is trained on signals generated from the input data itself, rather than pre-specified annotations. In LLM pretraining, for instance, the model can be trained to predict which token comes next in a text sequence. Self-supervised approaches like this can be helpful in reducing reliance on human-annotated data.
In the context of computer vision, approaches like contrastive learning (see CLIP) rely heavily on human-provided captions and metadata, restricting the model’s understanding to the quality of captions and the diversity of annotated images. DINOv2 overcomes these limitations by applying a self-supervised approach to vision tasks.
When pre-trained on a diverse set of 142M images and combined with basic task-specific heads, Meta’s DINOv2 backbone achieves state-of-the-art performance across a variety of vision tasks, from depth estimation to semantic segmentation. More to the point, the DINOv2 approach provides a template for anyone to train a high-quality model with few labeled images!
📚Additional Resources:
Gaussian Splatts Give NeRFs a Run for their Money

For the first half of 2023, Neural Radiance Fields (NeRFs) dominated discussions on novel view synthesis. As we documented in May, in advance of CVPR, the term “radiance” appeared 80% more often in CVPR 2023 paper titles than in CVPR 2022 paper titles.
The second half of 2023 has seen the emergence of an alternative method called Gaussian Splatting, which represents scenes with, well, 3-dimensional (or higher) Gaussians. The rasterization technique achieves SOTA visual quality and real-time (>100 fps) rendering. Gaussian splatting also has additional benefits compared to NeRFs, including much faster training.
📚Additional Resources:
- 3D Gaussian Splatting (original project)
- Dynamic 3D Gaussians
- 4D Gaussian Splatting
Text-to-Image Models Turn the Corner

In 2022, DALL-E 2 was named one of TIME Magazine’s 100 inventions of the year, Midjourney launched their v1, and Stable Diffusion was released, paving the way for text-to-image (T2I) models. The promise was there, but results were mixed — hands with six fingers, undesired spatial compositions, and unsatisfying aesthetic characteristics were all common. What’s more, image generation inference times could be substantial, slowing experimentation.
This year, T2I models have taken massive leaps forward. Midjourney creations have gone from somewhat recognizable to breathtakingly lifelike; DALL-E 3 refines your text prompt for you; Stable Diffusion XL can generate realistic faces and legible text; and Imagen 2 allows you to add invisible watermarks into your AI generated images.
I want to call attention to two tranches of innovation worth keeping an eye on as we move into 2024:
- The push toward real-time T2I generation: latent consistency models (LCM) and SDXL Turbo’s Adversarial Diffusion Distillation (ADD)
- Efforts to improve alignment of T2I generated images with human preferences: ImageReward and Pick-a-Pic.
In spite of all of these improvements, T2I models are still far from perfect. A team of researchers recently created the first holistic evaluation benchmark for T2I models (HEIM), and found that no single model excels across the board!
ControlNet
The dominant generative modeling technique underlying T2I models in 2023 is the diffusion model. In the context of image generation, a diffusion model is essentially tasked with iteratively turning a noisy initial image into a coherent, lower-noise image. This technique is incredibly powerful, but in a vacuum, exerting control over the final generated image via just a text prompt can be imprecise and unwieldy.
ControlNet enables a far greater degree of control over composition and style of the output of T2I diffusion models. With ControlNet, you can expressly control the contours of objects in the generated image from Canny edge maps or scribbles, the pose of a generated person, and so much more. If you’ve seen some of the stunning generative artwork that also functions as a working QR code, ControlNet is the technique behind it!
📚Additional Resources:
- Plugin to Add T2I images directly to your dataset
- Browse the (cleaned) ImageRewardDB dataset online
- Conquering ControlNet: Harness the Power of Diffusion Models with Higher-Quality Data
- GLIGEN: Open-Set Grounded Text-to-Image Generation
- Composer: Creative and Controllable Image Synthesis with Composable Conditions
LoRA: Flexible and Affordable Fine-tuning

Originally developed for fine-tuning LLMs, LoRA is a technique for parameter-efficient fine-tuning which makes adaptation of existing models easy, affordable, and accessible. The method works by inserting small, low-rank matrices in the base model, and learning a good configuration for these weights over the fine-tuning data while keeping the weights of the original model fixed. In effect, LoRA adapts the original model for a new purpose — all while adding just megabytes to GB-sized models!
The predominant application of LoRA in computer vision has been for fine-tuning diffusion models to match certain styles, from pixel art to voxels. There’s even a gallery of LoRA fine-tunes on Hugging Face! LoRA models have also been used to bring the reduced inference steps of latent consistency models to stable diffusion (LCM-LoRA).
But LoRA models are applicable in other vision contexts as well, from semantic segmentation to DreamBooth fine-tuning. One particularly interesting application of LoRA is DreamSim, where the technique is used to learn a SOTA human visual similarity metric.
📚Additional Resources:
- LoRA in Hugging Face Diffusers library
- Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
- DreamSim blog: learning perceptual similarity
- S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Ego-Exo4D: The Foundation Dataset for Video Perception
Over the past two years, researchers across Meta AI and 15 universities have worked together to collect the largest and highest quality dataset to-date for video learning and multimodal perception. This Ego-Exo4D dataset contains 1,400 hours of footage of 800+ participants performing skill-based human activities, from cooking to dancing, and has the potential to impact how both humans and robots learn and acquire skills.
For each scene, the dataset contains synchronized video footage from the first-person (egocentric) perspective, captured with Meta’s Aria glasses, and third-person (exocentric) perspective. This video data is augmented with first-person narrations, third-person play-by-plays, and annotations for tasks like 3D body and hand pose estimation. In conjunction with the dataset, Meta provides a benchmark suite, and plans to host a benchmark challenge in 2024.
📚Additional Resources:
Text-to-video Models Arrive

If generating images from text is hard, generating high-quality videos from text verges on impossible. Or at least that’s what many people thought heading into 2023. Over the past twelve months, however, the question has gone from an “if” to a “when”.
AI Creativity Tools powerhouse Runway has been leading the charge, releasing both Gen-1 and Gen-2 of its text-to-video (T2V) model, as well tools for frame interpolation and generating motion from masked regions. But Runway is far from the only player in the T2V game: in November, Pika Labs announced their “idea-to-video” platform and a $55M funding round, and Meta announced their SOTA model Emu Video, which splits T2V tasks into (i) text-conditioned image generation, and (ii) video generation conditioned on image and text prompt.
It is also worth mentioning a few open-source T2V models introduced in 2023:
- ModelScope’s Text-to-Video
- Text2Video-Zero from PicsArt
- VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
- AnimateZero: Video Diffusion Models are Zero-Shot Image Animators
While the quality of generated videos lags behind their commercial counterparts, the models form a solid foundation for open-source T2V efforts to come!
📚Additional Resources:
- Text-to-video model in Hugging Face Diffusers library
- Text2Video-Zero model in Hugging Face Diffusers library
- Synthesia: T2V platform for avatars
Multimodal LLMs
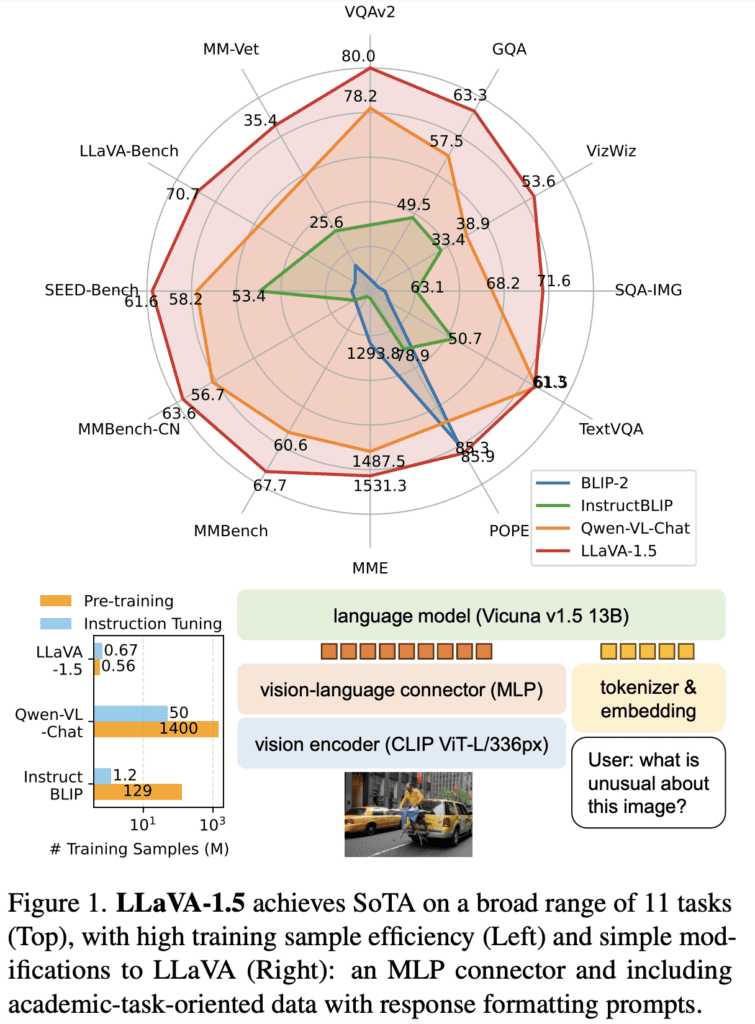
2023 was the year of LLMs after all, so we were bound to see LLMs go multimodal. LLMs are so powerful, the argument went, but they can only natively process text. If we want to let LLMs loose in the real world as agents, they will need other senses with which to perceive the world.
Multimodal LLMs (MLLMs) bridge this modality gap by giving an LLM the ability to accept tokens of more than one modality as input. In most cases, a pre-trained LLM is connected to a vision module with an adapter, whose weights are tuned through a multimodal task like image-text matching or contrastive learning.
The MLLMs which made the most noise were OpenAI’s GPT-4 Vision and Google DeepMind’s Gemini. Additional noteworthy (and open-source!) multimodal LLMs include LLaVA, CogVLM, InstructBLIP, Fuyu-8B, and IDEFICS.
📚Additional Resources:
- Browse the LLaVA-Instruct dataset online and dive deep into LLaVA
- Chat with your images using GPT-4 Vision
- Run VQA on your images using LLaVA-13B, Fuyu-8B, and BLIPv2
LLM-Aided Visual Reasoning

An alternative approach to bridging the modality gap is to use LLMs as reasoning engines, and allow them to invoke vision models. This approach disentangles the visual understanding and logical reasoning generally present in multimodal tasks, reducing the burden placed on vision models.
LLMs can act as reasoning engines, determining what specific vision tasks need to be performed, delegating the execution of these tasks to expert models, and drawing conclusions based on the outputs from these models. Such an approach is inherently modular (vision models can be added or replaced) and more interpretable (failures can be traced back to specific reasoning steps).
In 2023, we saw a variety of viral projects fitting this mold, including Chameleon, HuggingGPT, VisProg, and ViperGPT. The latter of these, ViperGPT, set a new SOTA for zero-shot visual question answering and grounded question answering tasks!
📚Additional Resources:
- VoxelGPT: An AI Assistant for Computer Vision
- Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
- A Dive into Vision-Language Models
- YouTube Video: How LLMs are Transforming Computer Vision
Conclusion
This post only scratches the surface of the vast ocean of advances we saw in 2023. If you enjoyed this and want to dive deeper into projects from specific conferences, check out these collections of 10 papers you won’t want to miss from CVPR 2023, ICCV 2023, or NeurIPS 2023. For last year’s recap of the top computer vision developments, check out Why 2022 was the most exciting year in computer vision history (so far).
Here are 10 other incredibly cool developments that I did not have space to cover but still deserve recognition include (in alphabetical order):
- Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation (Note: code not yet available)
- DEVA: Tracking Anything with Decoupled Video Segmentation
- Emu Edit: Precise Image Editing via Recognition and Generation Tasks
- GroundingDINO: State-of-the-art zero-shot object detector
- ImageBind: One Embedding Space To Bind Them All
- LEDITS++: Limitless Image Editing using Text-to-Image Models
- MagicBrush: A Manually Annotated Dataset for Instruction-Guided Image Editing
- MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
- SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation
- Stable Video Diffusion (Note: add SVD videos directly to your dataset with this workflow)
Let’s see what 2024 has in store!
What’s Next
Join the thousands of engineers and data scientists already using FiftyOne to solve some of the most challenging problems in computer vision today!
- ⭐ Star the FiftyOne GitHub repo (6,000+ stars and counting)
- 🎉 Join the 2,000-strong Slack community of ML engineers and data scientists!
- 🎉 Join 12,000+ in the AI, Machine Learning and Data Science meetup network!



